
您现在的位置是:java学习笔记 >
java学习笔记
java单链表反转
本 文 目 录

在数据结构的世界里,单链表是一种常见的线性数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。然而,当我们需要对单链表进行反转时,这不仅仅是一个简单的操作,它涉及到对链表节点连接方式的重新组织。
定义与目的
单链表反转,顾名思义,是将链表中的节点顺序颠倒过来的过程。例如,原本的链表是 A -> B -> C -> D,反转后变为 D -> C -> B -> A。这个过程的目的可能是为了简化某些算法的实现,或者为了满足特定的数据访问需求。
重要知识点
在实现单链表反转时,有几个关键点需要考虑:
- 头节点的处理:反转后的链表的头节点是原链表的尾节点。
- 节点指针的更新:在反转过程中,需要逐个更新节点的指针,使其指向前一个节点。
- 尾节点的确定:反转过程中需要跟踪当前的尾节点,以确保最后一个节点的指针被正确地设置为
null。
核心类与方法
在Java中,单链表通常由一个节点类(Node)和一个链表类(LinkedList)组成。
- 节点类:包含数据域和指向下一个节点的指针域。
- 链表类:包含指向头节点的指针,以及添加节点、删除节点、反转链表等方法。
使用场景
单链表反转在多种场景下都有其应用,例如:
- 算法竞赛:在某些算法题目中,链表反转是解决问题的第一步。
- 数据重组:在需要重新组织数据顺序的场景中,链表反转提供了一种灵活的方式。
- 功能测试:在软件开发过程中,链表反转可以作为测试链表操作正确性的一种手段。
代码案例
以下是两个单链表反转的Java代码案例。
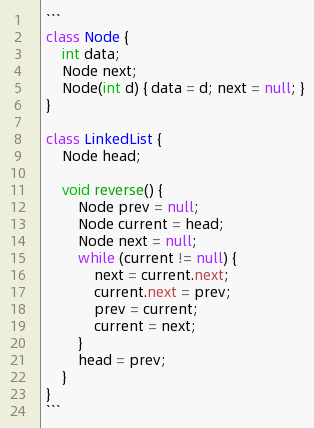
案例一:迭代方法
class Node {
int data;
Node next;
Node(int d) { data = d; next = null; }
}
class LinkedList {
Node head;
void reverse() {
Node prev = null;
Node current = head;
Node next = null;
while (current != null) {
next = current.next;
current.next = prev;
prev = current;
current = next;
}
head = prev;
}
}
案例二:递归方法
class Node {
int data;
Node next;
Node(int d) { data = d; next = null; }
}
class LinkedList {
Node head;
void reverseRecursive(Node current, Node prev) {
if (current == null) {
head = prev;
return;
}
Node next = current.next;
current.next = prev;
reverseRecursive(next, current);
}
void reverse() {
reverseRecursive(head, null);
}
}
补充知识表格
| 属性 | 描述 |
|---|---|
| 头节点 | 链表的第一个节点,反转后成为最后一个节点。 |
| 尾节点 | 链表的最后一个节点,反转后成为第一个节点。 |
| 指针更新 | 在反转过程中,每个节点的指针需要指向它的前一个节点。 |
| 递归反转 | 使用递归方法实现链表反转,简洁但可能遇到栈溢出问题。 |
| 迭代反转 | 使用循环实现链表反转,空间效率高,但代码稍复杂。 |
通过上述代码案例和表格,我们可以看到单链表反转可以通过迭代和递归两种方式实现。迭代方法空间效率高,但代码实现相对复杂;递归方法代码简洁,但需要注意栈溢出的风险。在实际应用中,选择哪种方法取决于具体需求和场景。

